Introduce register-efficient warp-wise Softmax (#15266)
improve softmax forward when number of elem to do softmax is between
(1024,2048]
several optimizations done in the PR:
1. originally ort will call softmax_block_forward when shape is 1500,
this will cause 5.53ms, however ort has another implementation called
softmax_warp_forward, this function will only need 4.74ms, so i modified
the function selection logic to call the faster version.
2. softmax_warp_forward will use register to cache the input in fp32
mode, this will consume many registers when data number is large and
will make warp occupancy quite low, also compiler can do some of its
optimizations, so the pr implements another version of
softmax_warp_forward, it will use shared memory instead of register to
cache the input; also when the for loop in the function has many
iterations, actually disable loop unrolling will make kernel faster
further.
the perf table between softmax_warp_forward1(the original version) and
softmax_warp_forward2
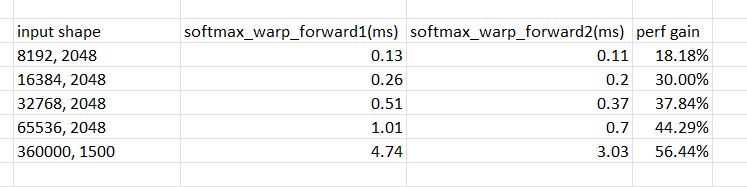
in open-ai whisper case, the kernel gain will be 5.53ms/3.03ms = 82%
(softmax_block_forward vs softmax_warp_forward2)

