[XNNPACK] Support running in multi-thread with seperate pthreadpool (#11762)
**Description**: Describe your changes.
XNNPACK takes pthreadpool as its internal threadpool implemtation, it
couples calculation and parallelization. Thus it's impossible to
leverage ORT's threadpool (EIGEN/OPENMP based). So we enabled
pthreadpool in XNNPACK EP in this PR.
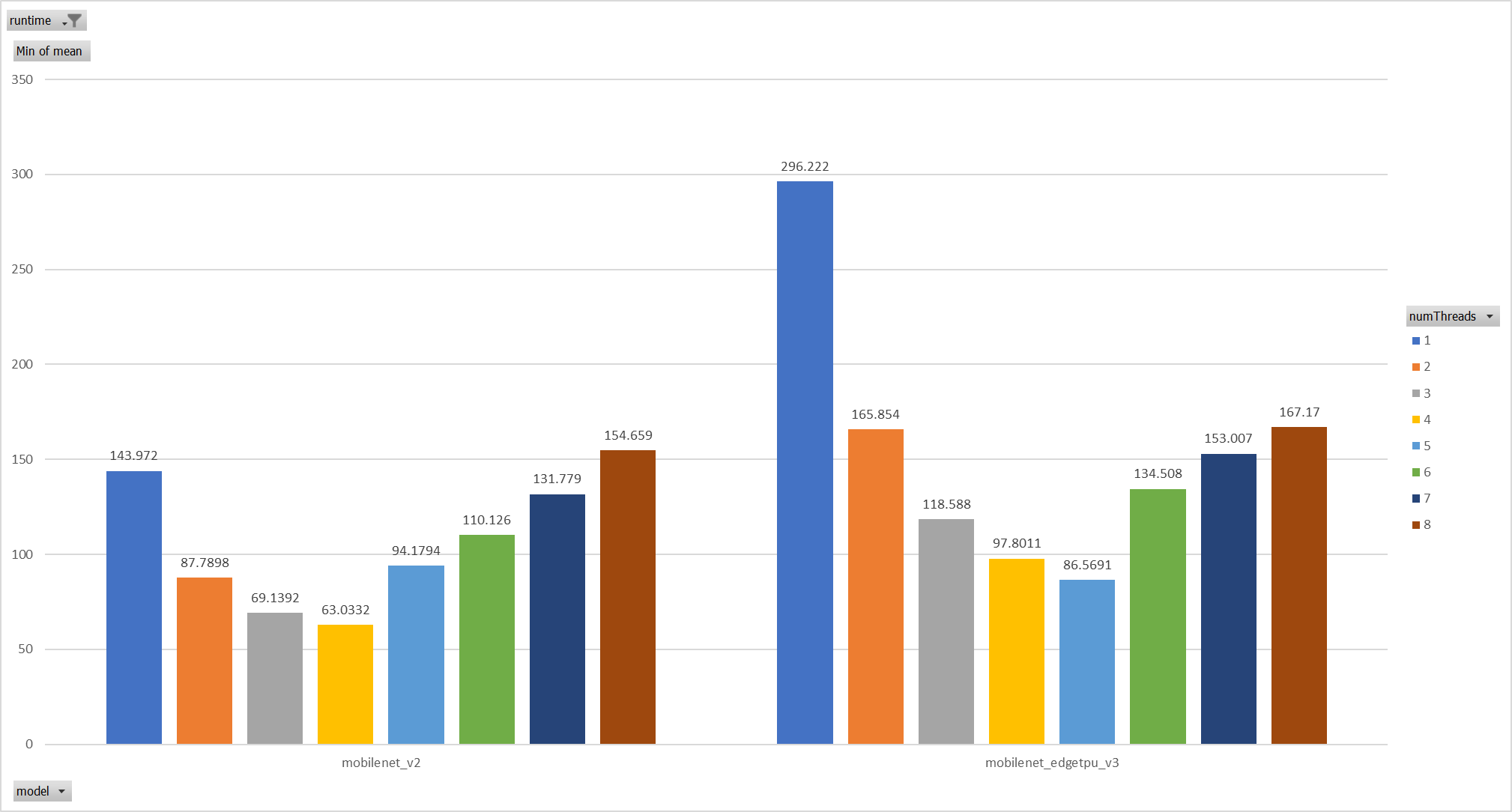
Case 1: Pthreadpool coexist with ORT-threadpool simply
Expriments setup
hardware:RedMi8A with 8 cores, ARMv7
The two threadpool has the same pool size form 1 to 8.
Two models: mobilenet_v2 and mobilenet_egetppu.
we can see the picture below and draw a conclusion, latency are even
higher from 5 threads or more.
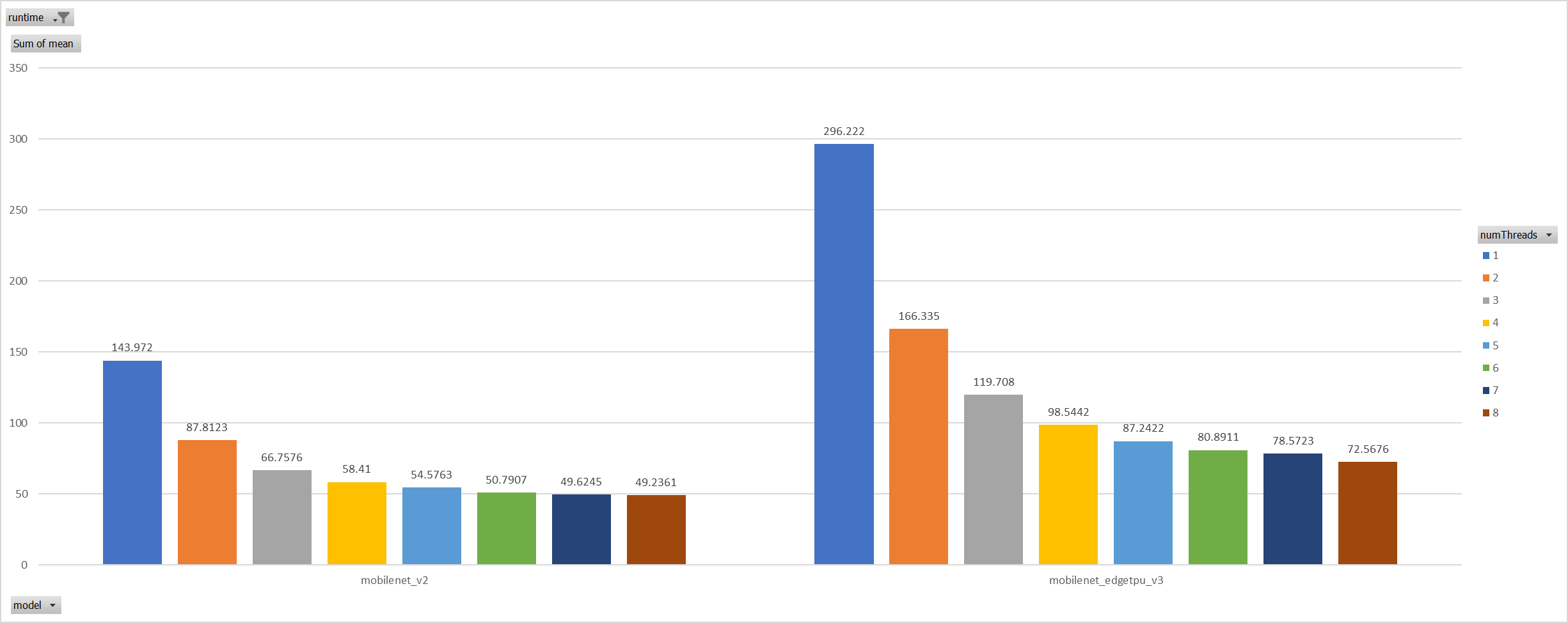
Case 2:
For the reason of performance regression with 5 more threads,
ORT-threads are spinning on CPU and diddn't realease it after
computation finished. It's equivalent of creating 5x2 threads for
parallelization while we have only 8 cpu cores.
So I mannuly disabled spinning after ort-threadpool finished and enabled
it when enter ort-threadpool.
The result is quite normal now.
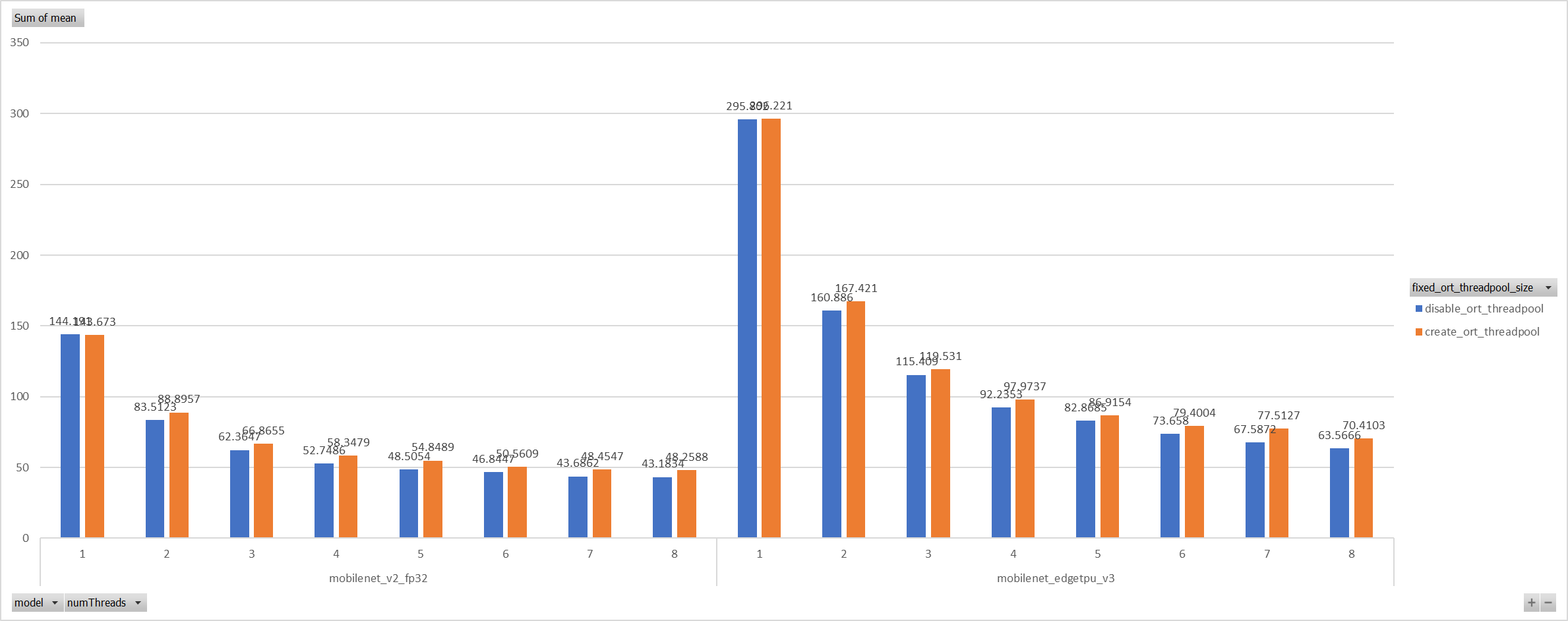
Case 3:
Even we achieved a reasonable results with disabling spinning, Will
ORT-threadpool still impact performance of pthreadpool?
we have expriment setting up as: Setting ORT-threadpool size
(intra_thread_num) as 1, and only pthreadpool created.
Attention that, almost a third of ops are running by CPU EP. we are
surprisingly find that disabling ort-threadpool is even better in
performance than creating two threadpool.
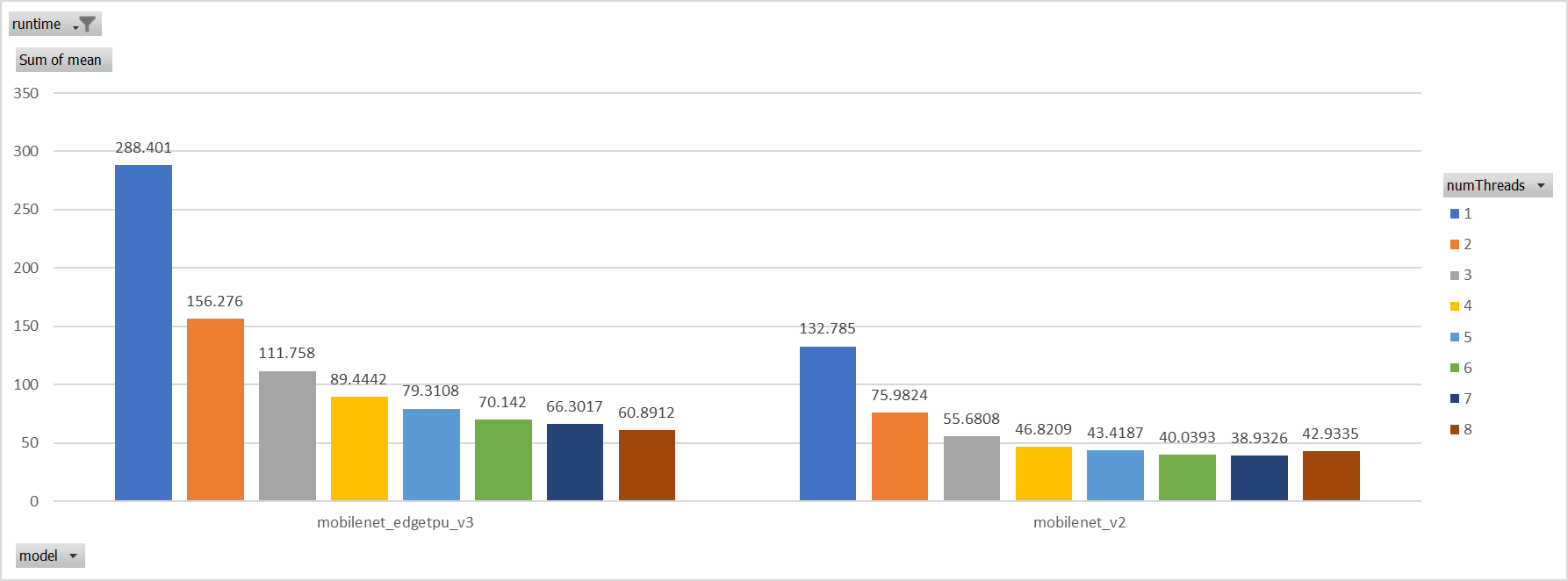
Case 4:
Use a unified threadpool between CPU ep and XNNPACK ep.
It's the fastest among all. But if we take the similar workload
partition strategy as ORT-threadpool, it could be faster.
**Motivation and Context**
- Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here.
Co-authored-by: Jicheng Wen <jicwen@microsoft.com>
 onnxruntime
f26054de - [XNNPACK] Support running in multi-thread with seperate pthreadpool (#11762)
onnxruntime
f26054de - [XNNPACK] Support running in multi-thread with seperate pthreadpool (#11762)
