
pytorch
04d7e167 - [quant] Quantized Average Pool Refactoring (#42009)
Commit
4 years ago[quant] Quantized Average Pool Refactoring (#42009)
Summary:
**cc** z-a-f. Refactor `qavg_pool(2,3)d_nhwc_kernel` as mentioned in https://github.com/pytorch/pytorch/issues/40316.
# Benchmarks
## Python
Before | After
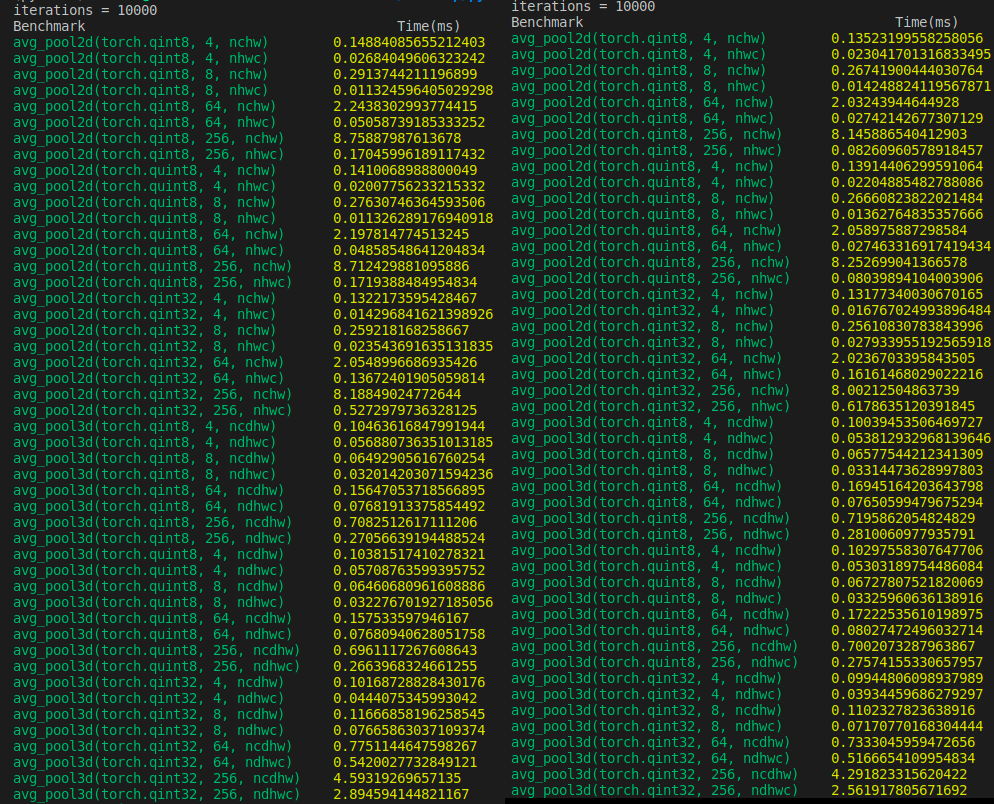
## C++
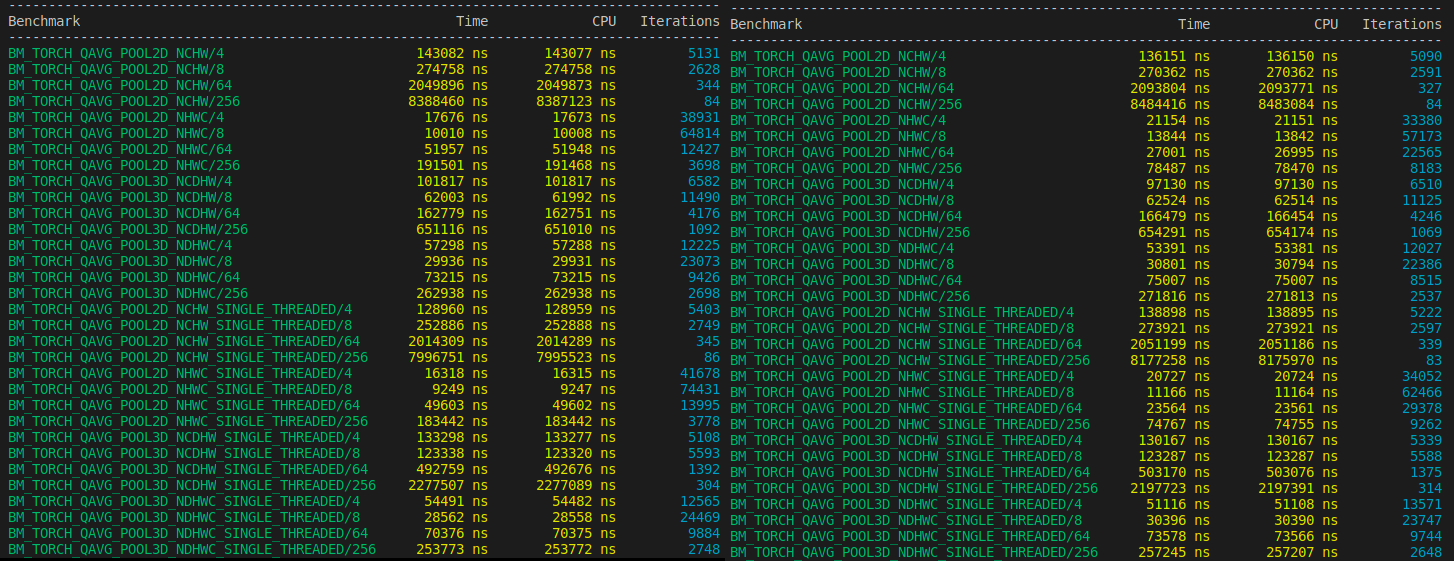
## Notes
- It does seem that for `qint8` and `quint8` there is a noticeable 2x increase in speed at least when the `channels > 64` in the benchmarks.
## Reproduce
### Python
```
import time
import numpy as np
import torch
from termcolor import colored
def time_avg_pool2d(X, kernel, stride, padding, ceil_mode, count_include_pad, divisor_override, iterations):
X, (scale, zero_point, torch_type) = X
qX_nchw = torch.quantize_per_tensor(torch.from_numpy(X), scale=scale,
zero_point=zero_point, dtype=torch_type)
qX_nhwc = qX_nchw.contiguous(memory_format=torch.channels_last)
assert(qX_nhwc.stride() != sorted(qX_nhwc.stride()))
assert(qX_nchw.is_contiguous(memory_format=torch.contiguous_format))
assert(qX_nhwc.is_contiguous(memory_format=torch.channels_last))
start = time.time()
for _ in range(iterations):
X_hat = torch.nn.quantized.functional.avg_pool2d(qX_nchw, kernel_size=kernel, stride=stride, padding=padding, ceil_mode=ceil_mode,
count_include_pad=count_include_pad, divisor_override=divisor_override)
qnchw_end = time.time() - start
start = time.time()
for _ in range(iterations):
X_hat = torch.nn.quantized.functional.avg_pool2d(qX_nhwc, kernel_size=kernel, stride=stride, padding=padding, ceil_mode=ceil_mode,
count_include_pad=count_include_pad, divisor_override=divisor_override)
qnhwc_end = time.time() - start
return qnchw_end*1000/iterations, qnhwc_end*1000/iterations
def time_avg_pool3d(X, kernel, stride, padding, ceil_mode, count_include_pad, divisor_override, iterations):
X, (scale, zero_point, torch_type) = X
qX_ncdhw = torch.quantize_per_tensor(torch.from_numpy(X), scale=scale,
zero_point=zero_point, dtype=torch_type)
qX_ndhwc = qX_ncdhw.contiguous(memory_format=torch.channels_last_3d)
assert(qX_ndhwc.stride() != sorted(qX_ndhwc.stride()))
assert(qX_ncdhw.is_contiguous(memory_format=torch.contiguous_format))
assert(qX_ndhwc.is_contiguous(memory_format=torch.channels_last_3d))
start = time.time()
for _ in range(iterations):
X_hat = torch.nn.quantized.functional.avg_pool3d(qX_ncdhw, kernel_size=kernel, stride=stride, padding=padding, ceil_mode=ceil_mode,
count_include_pad=count_include_pad, divisor_override=divisor_override)
qncdhw_end = time.time() - start
start = time.time()
for _ in range(iterations):
X_hat = torch.nn.quantized.functional.avg_pool3d(qX_ndhwc, kernel_size=kernel, stride=stride, padding=padding, ceil_mode=ceil_mode,
count_include_pad=count_include_pad, divisor_override=divisor_override)
qndhwc_end = time.time() - start
return qncdhw_end*1000/iterations, qndhwc_end*1000/iterations
iterations = 10000
print("iterations = {}".format(iterations))
print("Benchmark", "Time(ms)", sep="\t\t\t\t\t")
for torch_type in (torch.qint8, torch.quint8, torch.qint32):
for channel in (4,8,64,256):
X = np.random.rand(1, channel, 56, 56).astype(np.float32), (0.5, 1, torch_type)
ts = time_avg_pool2d(X, 4, None, 0, True, True, None, iterations)
print(colored("avg_pool2d({}, {}, {})".format(str(torch_type), channel, "nchw"), 'green'), colored(ts[0], 'yellow'), sep="\t")
print(colored("avg_pool2d({}, {}, {})".format(str(torch_type), channel, "nhwc"), 'green'), colored(ts[1], 'yellow'), sep="\t")
for torch_type in (torch.qint8, torch.quint8, torch.qint32):
for channel in (4,8,64,256):
X = np.random.rand(1, channel, 56, 56, 4).astype(np.float32), (0.5, 1, torch_type)
ts = time_avg_pool3d(X, 4, None, 0, True, True, None, iterations)
print(colored("avg_pool3d({}, {}, {})".format(str(torch_type), channel, "ncdhw"), 'green'), colored(ts[0], 'yellow'), sep="\t")
print(colored("avg_pool3d({}, {}, {})".format(str(torch_type), channel, "ndhwc"), 'green'), colored(ts[1], 'yellow'), sep="\t")
```
### C++
1. `git clone https://github.com/google/benchmark.git`
2. `git clone https://github.com/google/googletest.git benchmark/googletest`
```
# CMakeLists.txt
cmake_minimum_required(VERSION 3.10 FATAL_ERROR)
project(time_avg_pool VERSION 0.1.0)
find_package(Torch REQUIRED)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${TORCH_CXX_FLAGS}")
add_subdirectory(benchmark)
add_executable(time_average_pool time_average_pool.cpp)
target_link_libraries(time_average_pool ${TORCH_LIBRARIES})
set_property(TARGET time_average_pool PROPERTY CXX_STANDARD 14)
target_link_libraries(time_average_pool benchmark::benchmark)
```
```
// time_average_pool.cpp
#include <benchmark/benchmark.h>
#include <torch/torch.h>
torch::Device device(torch::kCPU);
static void BM_TORCH_QAVG_POOL2D_NCHW_SINGLE_THREADED(benchmark::State& state) {
torch::init_num_threads();
torch::set_num_threads(1);
auto x_nchw = torch::rand({1, state.range(0), 56, 56}, device);
auto qx_nchw = torch::quantize_per_tensor(x_nchw, 0.5, 1, torch::kQUInt8);
torch::Tensor X_hat;
for (auto _ : state)
X_hat = torch::nn::functional::avg_pool2d(
qx_nchw,
torch::nn::AvgPool2dOptions({4, 4}).ceil_mode(true).count_include_pad(
true));
}
static void BM_TORCH_QAVG_POOL2D_NHWC_SINGLE_THREADED(benchmark::State& state) {
torch::init_num_threads();
torch::set_num_threads(1);
auto x_nchw = torch::rand({1, state.range(0), 56, 56}, device);
auto qx_nchw = torch::quantize_per_tensor(x_nchw, 0.5, 1, torch::kQUInt8);
auto qx_nhwc = qx_nchw.contiguous(torch::MemoryFormat::ChannelsLast);
torch::Tensor X_hat;
for (auto _ : state)
X_hat = torch::nn::functional::avg_pool2d(
qx_nhwc,
torch::nn::AvgPool2dOptions({4, 4}).ceil_mode(true).count_include_pad(
true));
}
static void BM_TORCH_QAVG_POOL2D_NCHW(benchmark::State& state) {
auto x_nchw = torch::rand({1, state.range(0), 56, 56}, device);
auto qx_nchw = torch::quantize_per_tensor(x_nchw, 0.5, 1, torch::kQUInt8);
torch::Tensor X_hat;
for (auto _ : state)
X_hat = torch::nn::functional::avg_pool2d(
qx_nchw,
torch::nn::AvgPool2dOptions({4, 4}).ceil_mode(true).count_include_pad(
true));
}
static void BM_TORCH_QAVG_POOL2D_NHWC(benchmark::State& state) {
auto x_nchw = torch::rand({1, state.range(0), 56, 56}, device);
auto qx_nchw = torch::quantize_per_tensor(x_nchw, 0.5, 1, torch::kQUInt8);
auto qx_nhwc = qx_nchw.contiguous(torch::MemoryFormat::ChannelsLast);
torch::Tensor X_hat;
for (auto _ : state)
X_hat = torch::nn::functional::avg_pool2d(
qx_nhwc,
torch::nn::AvgPool2dOptions({4, 4}).ceil_mode(true).count_include_pad(
true));
}
static void BM_TORCH_QAVG_POOL3D_NCDHW_SINGLE_THREADED(
benchmark::State& state) {
torch::init_num_threads();
torch::set_num_threads(1);
auto x_ncdhw = torch::rand({1, state.range(0), 56, 56, 4}, device);
auto qx_ncdhw = torch::quantize_per_tensor(x_ncdhw, 0.5, 1, torch::kQUInt8);
torch::Tensor X_hat;
for (auto _ : state)
X_hat = torch::nn::functional::avg_pool3d(
qx_ncdhw,
torch::nn::AvgPool3dOptions({5, 5, 5})
.ceil_mode(true)
.count_include_pad(true));
}
static void BM_TORCH_QAVG_POOL3D_NDHWC_SINGLE_THREADED(
benchmark::State& state) {
torch::init_num_threads();
torch::set_num_threads(1);
auto x_ncdhw = torch::rand({1, state.range(0), 56, 56, 4}, device);
auto qx_ncdhw = torch::quantize_per_tensor(x_ncdhw, 0.5, 1, torch::kQUInt8);
auto qx_ndhwc = qx_ncdhw.contiguous(torch::MemoryFormat::ChannelsLast3d);
torch::Tensor X_hat;
for (auto _ : state)
X_hat = torch::nn::functional::avg_pool3d(
qx_ndhwc,
torch::nn::AvgPool3dOptions({5, 5, 5})
.ceil_mode(true)
.count_include_pad(true));
}
static void BM_TORCH_QAVG_POOL3D_NCDHW(benchmark::State& state) {
auto x_ncdhw = torch::rand({1, state.range(0), 56, 56, 4}, device);
auto qx_ncdhw = torch::quantize_per_tensor(x_ncdhw, 0.5, 1, torch::kQUInt8);
torch::Tensor X_hat;
for (auto _ : state)
X_hat = torch::nn::functional::avg_pool3d(
qx_ncdhw,
torch::nn::AvgPool3dOptions({5, 5, 5})
.ceil_mode(true)
.count_include_pad(true));
}
static void BM_TORCH_QAVG_POOL3D_NDHWC(benchmark::State& state) {
auto x_ncdhw = torch::rand({1, state.range(0), 56, 56, 4}, device);
auto qx_ncdhw = torch::quantize_per_tensor(x_ncdhw, 0.5, 1, torch::kQUInt8);
auto qx_ndhwc = qx_ncdhw.contiguous(torch::MemoryFormat::ChannelsLast3d);
torch::Tensor X_hat;
for (auto _ : state)
X_hat = torch::nn::functional::avg_pool3d(
qx_ndhwc,
torch::nn::AvgPool3dOptions({5, 5, 5})
.ceil_mode(true)
.count_include_pad(true));
}
BENCHMARK(BM_TORCH_QAVG_POOL2D_NCHW)->RangeMultiplier(8)->Range(4, 256);
BENCHMARK(BM_TORCH_QAVG_POOL2D_NHWC)->RangeMultiplier(8)->Range(4, 256);
BENCHMARK(BM_TORCH_QAVG_POOL3D_NCDHW)->RangeMultiplier(8)->Range(4, 256);
BENCHMARK(BM_TORCH_QAVG_POOL3D_NDHWC)->RangeMultiplier(8)->Range(4, 256);
BENCHMARK(BM_TORCH_QAVG_POOL2D_NCHW_SINGLE_THREADED)
->RangeMultiplier(8)
->Range(4, 256);
BENCHMARK(BM_TORCH_QAVG_POOL2D_NHWC_SINGLE_THREADED)
->RangeMultiplier(8)
->Range(4, 256);
BENCHMARK(BM_TORCH_QAVG_POOL3D_NCDHW_SINGLE_THREADED)
->RangeMultiplier(8)
->Range(4, 256);
BENCHMARK(BM_TORCH_QAVG_POOL3D_NDHWC_SINGLE_THREADED)
->RangeMultiplier(8)
->Range(4, 256);
BENCHMARK_MAIN();
```
3. `mkdir build && cd build`
4. ```cmake -DCMAKE_BUILD_TYPE=Release -DCMAKE_PREFIX_PATH=`python -c 'import torch;print(torch.utils.cmake_prefix_path)'` .. ```
5. `cmake --build . --config Release`
6. `./time_average_pool`
# Further notes
- I've used `istrideB, istrideD, istrideH, strideW, strideC` to match `_qadaptive_avg_pool_kernel` since there's some code duplication there as mentioned in https://github.com/pytorch/pytorch/issues/40316.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42009
Reviewed By: pbelevich
Differential Revision: D22794441
Pulled By: z-a-f
fbshipit-source-id: 16710202811a1fbe1c99ea4d9b45876d6d28a8da
Author

Committer

Parents
Loading