[FSDP] Auto-pad for no `pad()` in post-bwd hook (`use_orig_params=True`) (#99054)
This avoids the post-backward `F.pad()` call before reduce-scatter for `use_orig_params=True`. It is pretty cool that we built up all of the necessary infra in past PRs so that this change is simple.
We simply append one more padding tensor to pad out the `FlatParameter` numel to be divisible by the world size. This causes the flat gradient to be computed directly with the padded size, removing the need for the explicit `F.pad()` call.
Because the infra is built out right now for `use_orig_params=True`, we only add this auto-pad logic for that path. We can add it for `use_orig_params=False` if needed in follow-up work.
I confirmed in local tests that this removes the pad call.
Before (yes `aten::pad`):

After (no `aten::pad`):
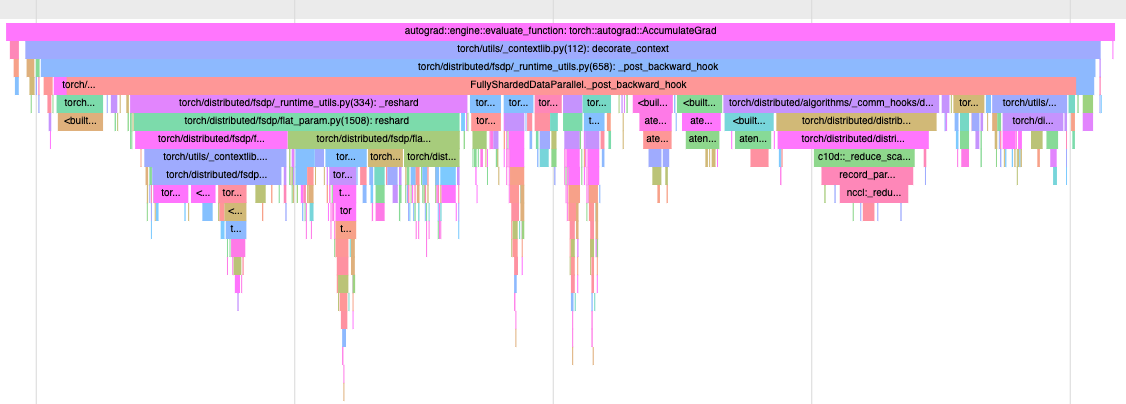
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99054
Approved by: https://github.com/fegin, https://github.com/zhaojuanmao
 pytorch
0a98d943 - [FSDP] Auto-pad for no `pad()` in post-bwd hook (`use_orig_params=True`) (#99054)
pytorch
0a98d943 - [FSDP] Auto-pad for no `pad()` in post-bwd hook (`use_orig_params=True`) (#99054)

