onnx export of fake quantize functions (#39738)
Summary:
As discussed in https://github.com/pytorch/pytorch/issues/39502.
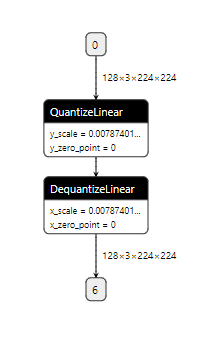
This PR adds support for exporting `fake_quantize_per_tensor_affine` to a pair of `QuantizeLinear` and `DequantizeLinear`.
Exporting `fake_quantize_per_channel_affine` to ONNX depends on https://github.com/onnx/onnx/pull/2772. will file another PR once ONNX merged the change.
It will generate ONNX graph like this:
jamesr66a
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39738
Reviewed By: hl475
Differential Revision: D22517911
Pulled By: houseroad
fbshipit-source-id: e998b4012e11b0f181b193860ff6960069a91d70


