Optimize PReLU (float32) and enable PReLU BFloat16 support in CPU path
In this PR, we try to optimize PReLU op in CPU path, and enable BFloat16 support based on the optimized PReLU.
The original implementation uses parallel_for to accelerate operation speed, but vectorization is not used. It can be optimized by using TensorIterator, both including parallelization and vectorization.
The difference between PReLU and other activation function ops, is that PReLU supports a learnable parameter `weight`. When called without arguments, nn.PReLU() uses a single parameter `weight` across all input channels. If called with nn.PReLU(nChannels), a separate `weight` is used for each input channel. So we cannot simply use TensorIterator because `weight` is different for each input channel.
In order to use TensorIterator, `weight` should be broadcasted to `input` shape. And with vectorization and parallel_for, this implementation is much faster than the original one. Another advantage is, don't need to separate `share weights` and `multiple weights` in implementation.
We test the performance between the PReLU implementation of public Pytorch and the optimized PReLU in this PR, including fp32/bf16, forward/backward, share weights/multiple weights configurations. bf16 in public Pytorch directly reuses `Vectorized<scalar_t>` for `BFloat16`.
Share weights:
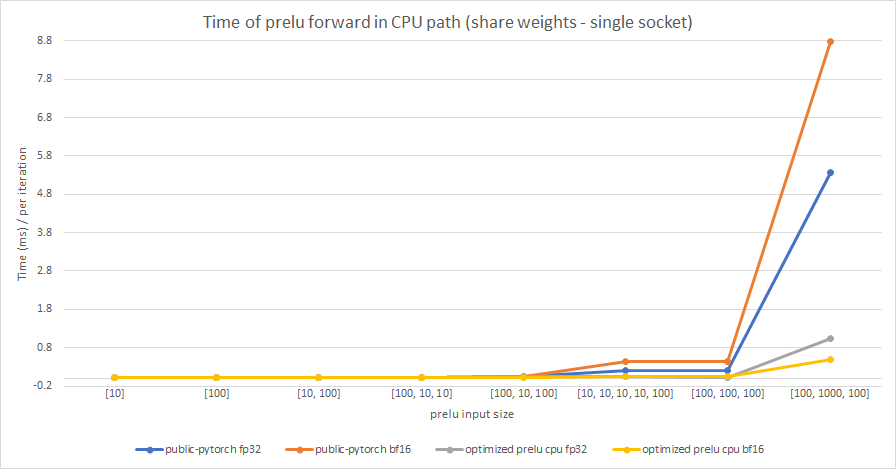
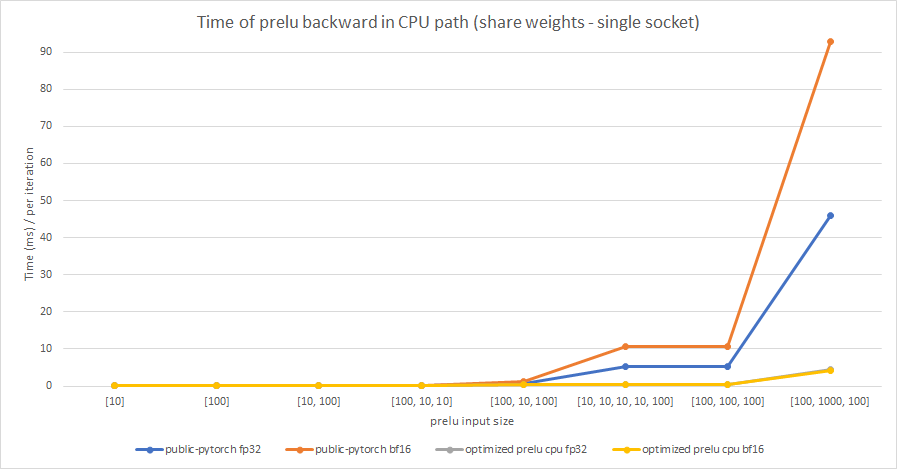
Multiple weights:
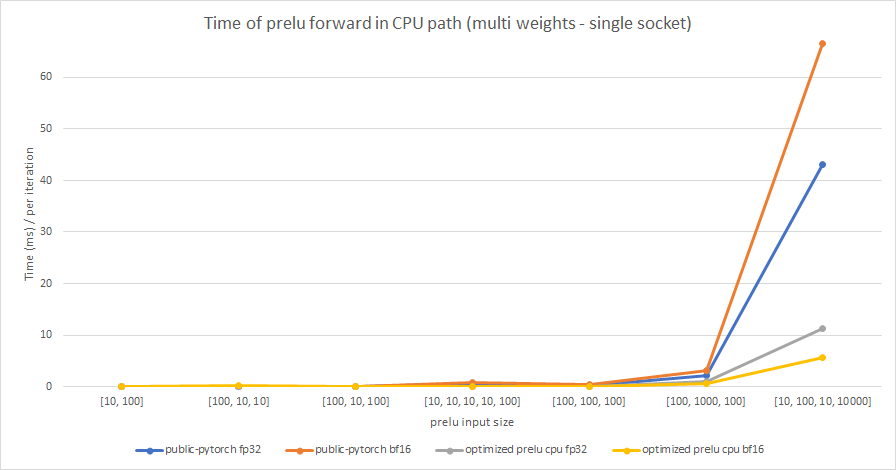
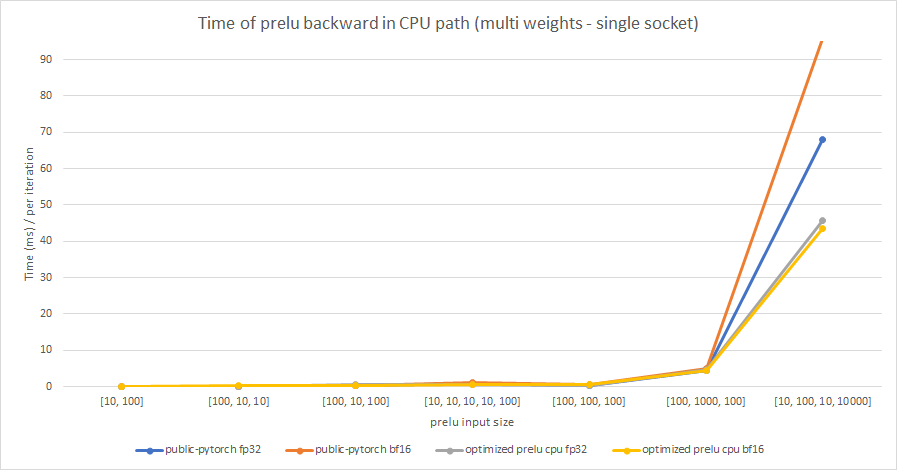
cc @albanD @mruberry @jbschlosser @walterddr
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63634
Approved by: https://github.com/frank-wei, https://github.com/seemethere
 pytorch
263c4c2a - Optimize PReLU (float32) and enable PReLU BFloat16 support in CPU path
pytorch
263c4c2a - Optimize PReLU (float32) and enable PReLU BFloat16 support in CPU path

