[Autograd] `expand_as` instead of `clone` to get `AccumulateGrad` (#96356)
This PR makes a minor change to the multi-grad hook implementation. This should decrease peak memory since we avoid one `clone()` per tensor passed into the multi-grad hook. Let me know if there are technical reasons why we need to clone. If so, is there a way for some use cases to not clone?
Before with `clone()`:
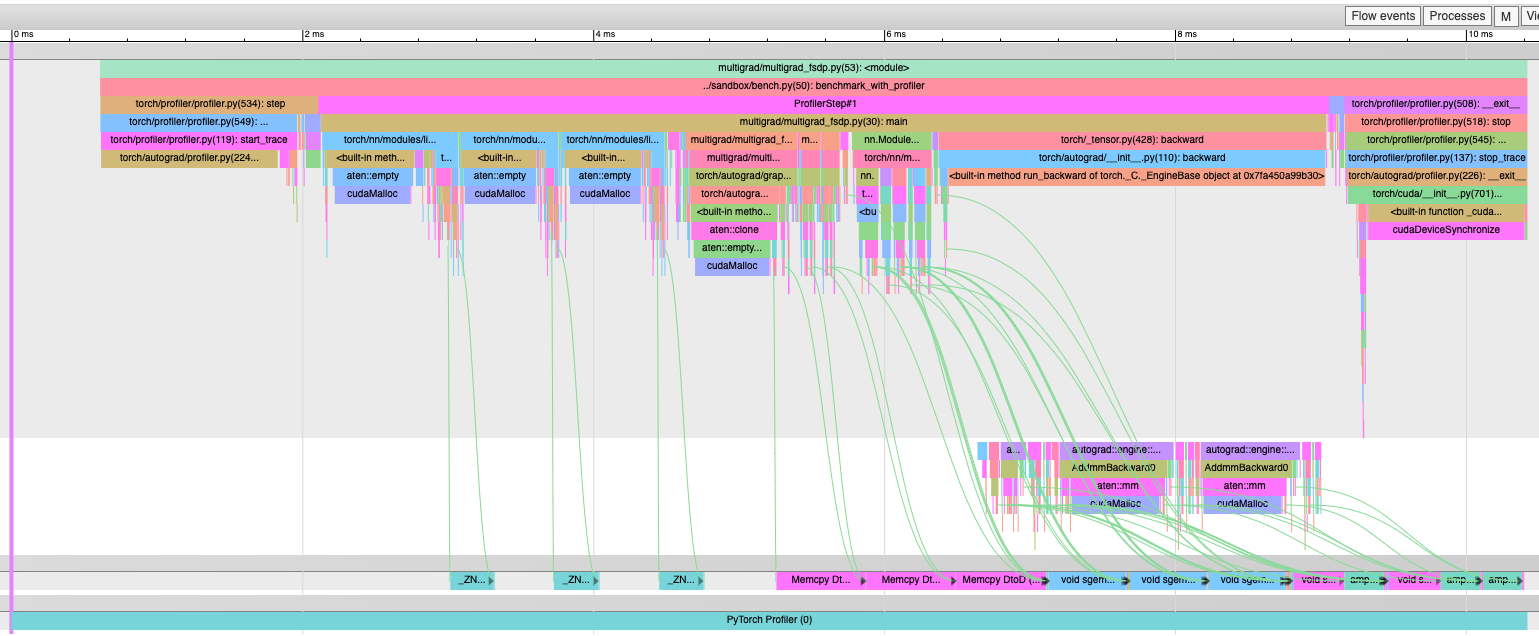
After with `expand_as()` -- no more "Memcpy DtoD" kernels:
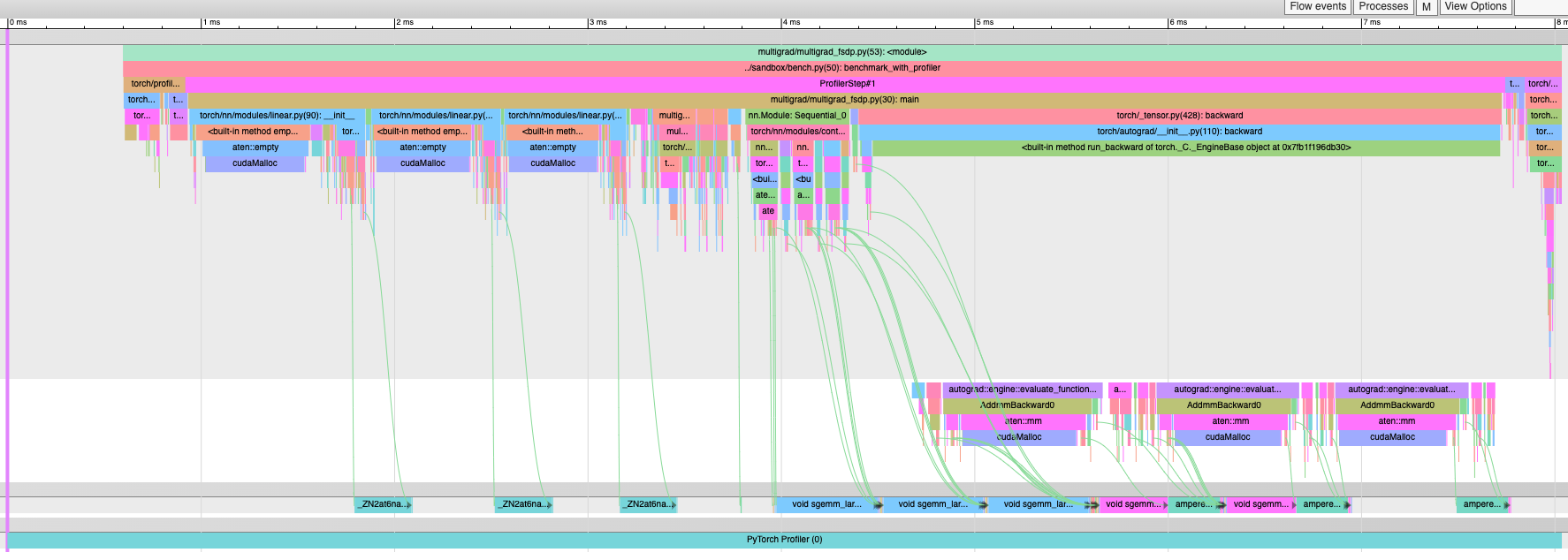
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96356
Approved by: https://github.com/soulitzer
 pytorch
457396fc - [Autograd] `expand_as` instead of `clone` to get `AccumulateGrad` (#96356)
pytorch
457396fc - [Autograd] `expand_as` instead of `clone` to get `AccumulateGrad` (#96356)

