Avoid elementwise dispatch of gradient unscaling/validation ops in `_foreach_non_finite_check_and_unscale_cpu_` (#100108)
Fixes [#82206](https://github.com/pytorch/pytorch/issues/82206)
When executing a `ShardedGradScaler` step in the context of `cpu_offload`, [the function](https://github.com/pytorch/pytorch/blob/ecd2c71871f8bf9a9fa4a4d875609b0922061a6f/torch/distributed/fsdp/sharded_grad_scaler.py#L151-L152) `_foreach_non_finite_check_and_unscale_cpu_` is grindingly slow. This issue is due to the elementwise op dispatching/redispatching/execution that is engendered by the current approach to gradient tensor validation:
https://github.com/pytorch/pytorch/blob/ecd2c71871f8bf9a9fa4a4d875609b0922061a6f/torch/distributed/fsdp/sharded_grad_scaler.py#L159-L163
The subsequent `isinf` and `isnan` checks with associated `any` checks result in unscalable elementwise op dispatches:
https://github.com/pytorch/pytorch/blob/ecd2c71871f8bf9a9fa4a4d875609b0922061a6f/torch/distributed/fsdp/sharded_grad_scaler.py#L173-L181
This inefficency is of course hidden in the current FSDP tests given their (appropriately) trivial parameter dimensionality. In the perf analysis below, the example test configures only the final `Linear(4, 8)` module parameters to require grad, so there are 40 elements to iterate through. However, if one increases the dimensionality to a still-modest 320008 elements (changing the final module to `Linear(40000,8)`), the execution time/cpu cost of the test is dominated by the elementwise op dispatching/redispatching/execution of the `any` validation ops in this function.
To characterize the current behavior, I use a slightly modified version of an existing `ShardedGradScaler` test [^1]. The following modifications to the test are made to allow the analysis:
1. Run just `CUDAInitMode.CUDA_BEFORE` for clarity instead of additional scenarios
2. Increase the final module to `Linear(40000, 8)` (along with modifying the preceding module to make the dimensions work) ,
3. For the cProfile run (but not valgrind or perf) the test runs just a single [`_train_for_several_steps`](https://github.com/pytorch/pytorch/blob/ecd2c71871f8bf9a9fa4a4d875609b0922061a6f/torch/testing/_internal/common_fsdp.py#L926-L934) step per rank (instead of 2 steps)
4. I temporarily reduce `init_scale` further to ensure we don't hit any `infs`, short-circuiting our analysis
### Current behavior
The most relevant call subgraph:
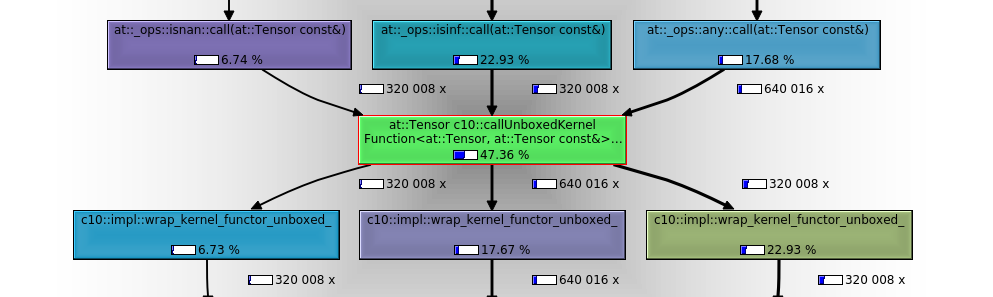
Note that:
1. Instead of dispatching to the relevant autograd op and then redispatching to the relevant CPU op implementation 8 times per test, (2 train steps x 2 any calls per parameter per step x 2 orig parameters) we (I believe unnecessarily) call the relevant dispatch flow elementwise, so 640016 times! (only 1 node in this trace so 320008 elements/2 X 2 train steps x 2 calls per element per step).
2. Nearly 50% of the relative (inclusive) instruction reads for the entire test in `callgrind` are executed by the `isnan` (320008 execs), `isinf` (320008 execs) and `any` (640016 execs) calls.
3. The `any` pre-dispatch entry point IRs (`torch::autograd::THPVariable_any`) vs actual op implementation IRs (`at::native::structured_any_all_out::impl`) are below to give one a sense of the relative dispatch and op execution cost in an elementwise context[^3].


Using cprofile stats:
```bash
python -c "import pstats; stats=pstats.Stats('/tmp/fsdp_cprofile_8wa9uw39.stats'); stats.print_stats()"
...
ncalls tottime percall cumtime percall filename:lineno(function)
1 20.159 20.159 66.805 66.805 torch/distributed/fsdp/sharded_grad_scaler.py:151(_foreach_non_finite_check_and_unscale_cpu_)
160004 18.427 0.000 18.427 0.000 {built-in method torch.isinf}
160004 6.026 0.000 6.026 0.000 {built-in method torch.isnan}
```
We see that a single step of the scaler runs for more than a minute. Though there is non-trivial cprofile overhead, we can infer from this that per-element op dispatches/executions are on the order of a 100ns.
On the order of 100 nanoseconds per dispatch is acceptable if we're using typical tensor access patterns, but if we're dispatching each element for each op, obviously everything is going to come to a grinding halt for many practical use cases.
(Given the cost of this function is currently O(n) in the number of gradient elements, feel free to set `TORCH_SHOW_DISPATCH_TRACE=1` if you want to make this function cry :rofl:)
I've attached a flamegraph at the bottom of the PR[^2] that more intuitively demonstrates the manner and extent of resource consumption attributable to this function with just a modest number of gradient elements.
### After the loop refactor in this PR:
The most relevant call subgraph:

Note that:
1. Less than 0.4% of the relative (inclusive) instruction reads for the entire test in `callgrind` are executed by the `isnan` (4 execs), `isinf` (4 execs) and `any` (8 execs) calls (versus ~50% and 320008, 320008, 640016 respectively above)
2. The `any` pre-dispatch entry point IRs (`torch::autograd::THPVariable_any`) vs actual op implementation IRs (`at::native::structured_any_all_out::impl`) reflect far less overhead (of secondary importance to item number 1)


Using cprofile stats:
```bash
python -c "import pstats; stats=pstats.Stats('/tmp/fsdp_cprofile_pfap7nwk.stats'); stats.print_stats()"
...
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.013 0.013 0.109 0.109 torch/distributed/fsdp/sharded_grad_scaler.py:151(_foreach_non_finite_check_and_unscale_cpu_)
2 0.022 0.011 0.022 0.011 {built-in method torch.isinf}
2 0.018 0.009 0.018 0.009 {built-in method torch.isnan}
```
We can see our function runtime has dropped from more than a minute to ~100ms.
### Assumptions associated with this loop refactor:
The key assumptions here are:
1. The grads are always on CPU in this function so any MTA-safe constraints ([`can_use_fast_route`](https://github.com/pytorch/pytorch/blob/efc3887ea508b3cfd94603fd8afe4e8cf6dce7b7/aten/src/ATen/native/cuda/AmpKernels.cu#L110-L111) relating to the relevant CUDA kernel path selection, i.e. slower `TensorIterator` gpu kernel vs `multi_tensor_apply_kernel`) do not apply in this context
2. We've already filtered by dtype and device and can assume the presence of a single CPU device. Unless manually creating separate CPU devices with manually set non-default indexes (which I don't think FSDP supports and should be validated prior to this function), device equality should always be `True` for `cpu` type devices so we should just need to check that the current device is of `cpu` type. [^4].

[^1]: `TestShardedGradScalerParityWithDDP.test_fsdp_ddp_parity_with_grad_scaler_offload_true_none_mixed_precision_use_orig_params` test in `test/distributed/fsdp/test_fsdp_sharded_grad_scaler.py`
[^2]: Note the native frame stacks for `torch::autograd::THPVariable_isinf`, `torch::autograd::THPVariable_isnan`, `torch::autograd::THPVariable_any` in particular.
[^3]: There's more `TensorIterator` etc. setup overhead further up the stack beyond `structured_any_all_out`, but roughly speaking
[^4]: Device equality is based on [type and index combination](https://github.com/pytorch/pytorch/blob/efc3887ea508b3cfd94603fd8afe4e8cf6dce7b7/c10/core/Device.h#L47-L51), CPU device type is -1 by default (`None` on the python side) and is intended to [always be 0](https://github.com/pytorch/pytorch/blob/cf21240f67a2dd316f3c9e41e3b9d61d4abac07a/c10/core/Device.h#L29) if set explicitly. Though technically, unless in debug mode, this constraint isn't [actually validated](https://github.com/pytorch/pytorch/blob/bb4e9e9124a81859de6ac1ef0c0798643cb9b7a6/c10/core/Device.h#L171-L184), so one can actually manually create separate `cpu` devices with invalid indices. I suspect it's safe to ignore that potential incorrect/unusual configuration in this context but let me know if you'd like to add another `cpu` device equality check.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100108
Approved by: https://github.com/awgu
 pytorch
477ca178 - Avoid elementwise dispatch of gradient unscaling/validation ops in `_foreach_non_finite_check_and_unscale_cpu_` (#100108)
pytorch
477ca178 - Avoid elementwise dispatch of gradient unscaling/validation ops in `_foreach_non_finite_check_and_unscale_cpu_` (#100108)

