Parallelize `gatherTopK` on multiple blocks (#74267)
This PR adds `mbtopk::gatherTopK` which uses the same number of blocks as `radixFindKthValues` to gather top k values in parallel. With this new `gatherTopK` kernel, the sort path is no longer needed because `best(mb, sb)` now is always better than the sort path.
## Algorithm
During each pass of `radixFindKthValues`, this kernel will output per slice `desired` and per block digit counters. After every pass, I use kernel `computeBlockwiseWithinKCounts` to compute the number of elements that `>kthValue`(if largest) or `<kthValue`(if !largest) for each block from the per slice `desired` and per block digit counters. After the last pass, I use ~kernel `computeBlockwiseKthCounts`~ (~edit: fancy iterator~ edit 2: fancy iterator is too large in binary size, so I decided to use `computeBlockwiseKthCounts` in the end) to compute the number of elements that `==kthValue` for each block from the per slice `desired` and per block digit counters. Then I use cub's scan-by-key algorithm to compute the indices in output where each block should write its output to. Then I used the `mbtopk::gatherTopK` to write top k elements to these indices.
## Benchmark
Using script from @yueyericardo: https://github.com/yueyericardo/misc/blob/master/share/topk-script/benchmark.py
I get the following result on RTX3090:
**New mb vs old mb speedup:**
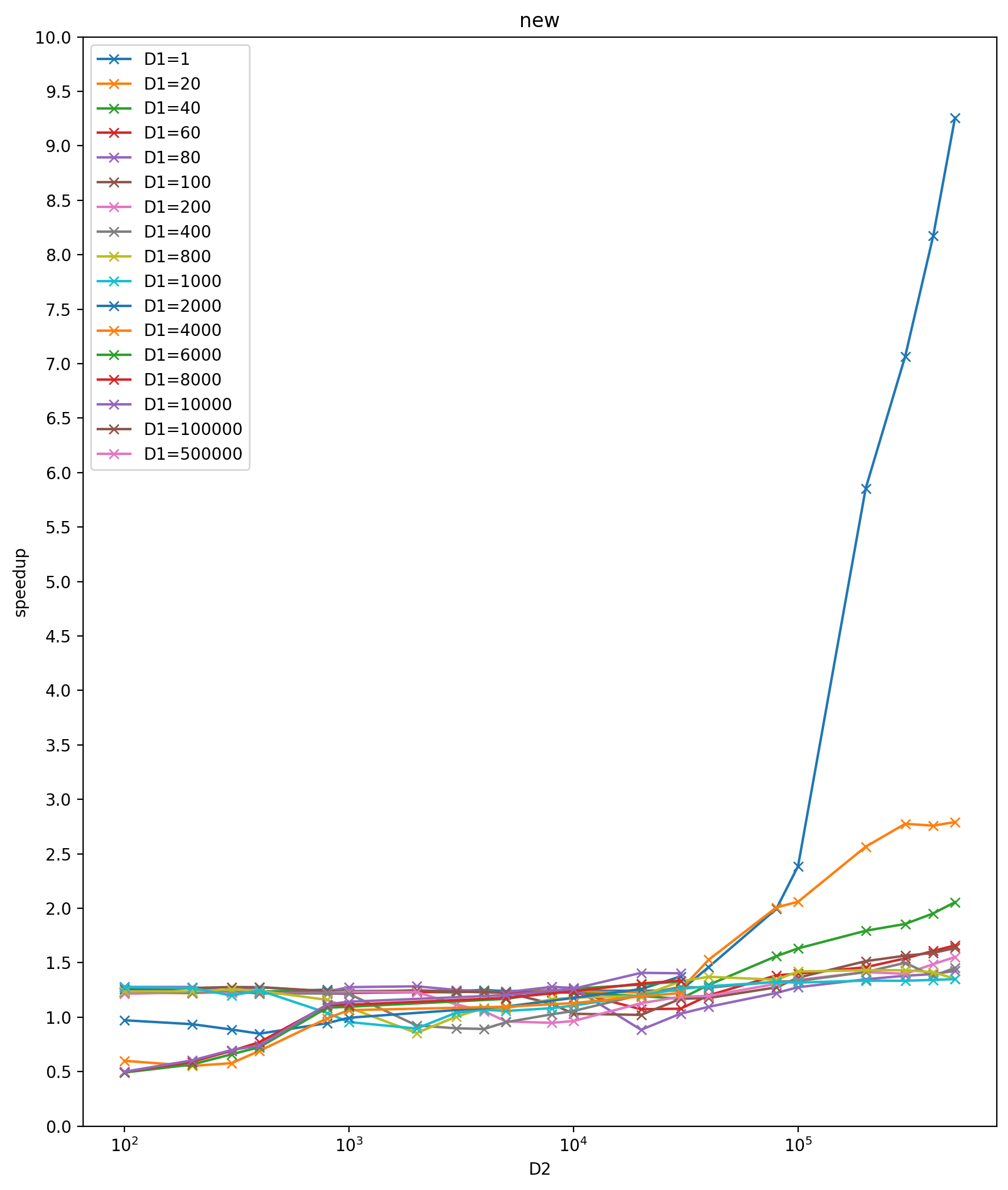
**New dispatched vs old dispatched speedup:**
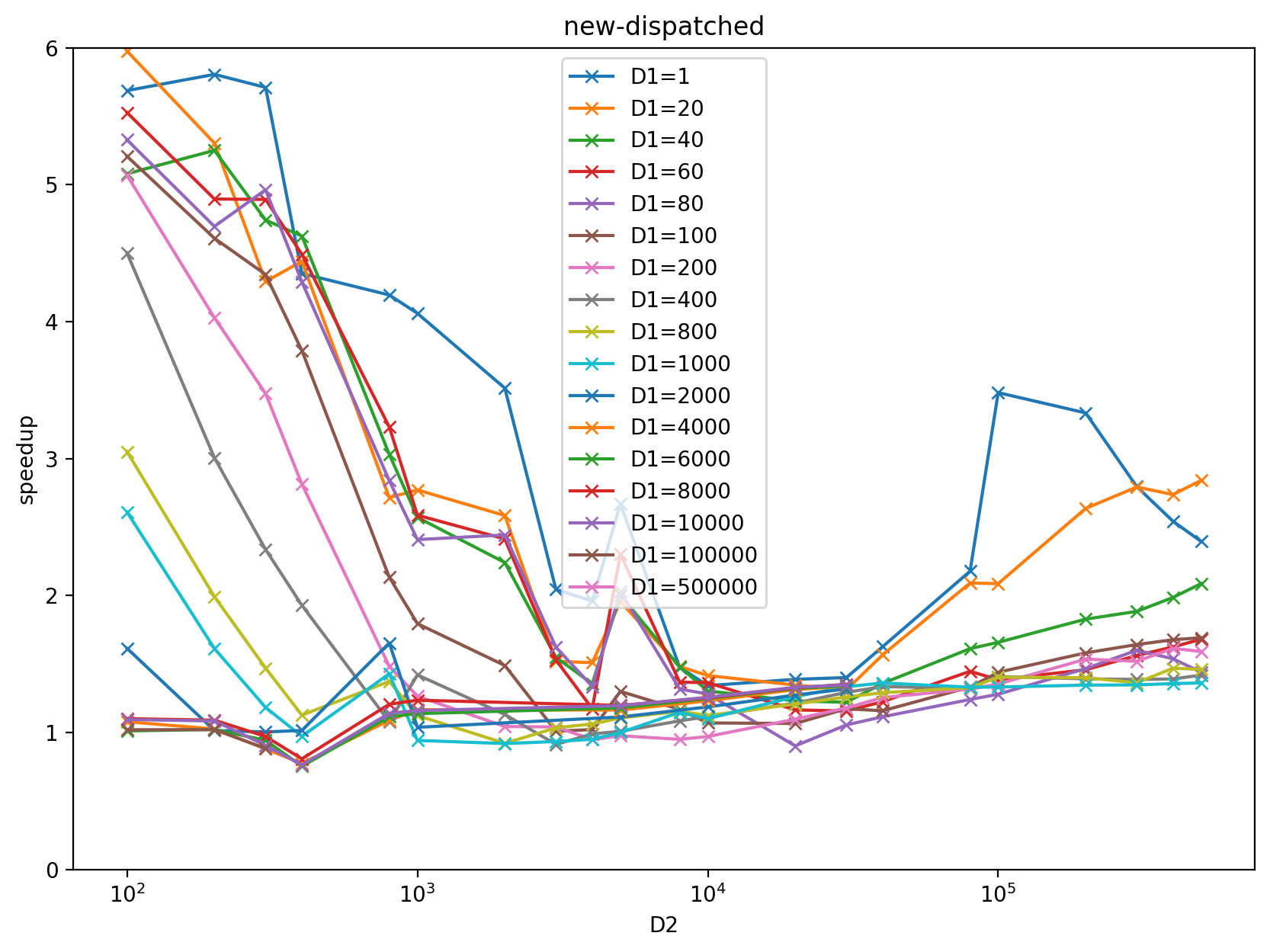
Raw data in: https://docs.google.com/spreadsheets/d/e/2PACX-1vQxECU_qP1G-skQ8DmJDo-hx0OYPiJ01EkJMSZQdzfWj-QxhScQCkj9Z3KKBc7svEA6DC03UNvD1ial/pubhtml
This spreadsheet shows that the sort path is no longer needed: `best(mb, sb)` now is always better than the sort path.
cc: @yueyericardo @ngimel @ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74267
Approved by: https://github.com/ngimel


