Add native impl for group norm on quantized CPU for channels-last inputs (#70520)
**Description**
This PR adds a native implementation for group norm on quantized CPU for channels-last inputs. It will also be used by instance norm since the latter would call group norm kernel eventually.
For channels last, group norm has an input shape of `{N, H, W, GD}`, mean and rstd are collected per each n and g, which involves reduction on non-adjacent dimensions. We can parallel in the following 2 impls:
- impl-1: parallel on `N * G`. Only need one omp session but memory access per thread is non-contiguous.
- impl-2: parallel on `N * HxW`. Memory access per thread is contiguous but requires help of extra temp buffer of size `{T, N, 2C}`.
Generally, impl-2 has better performance when `HxW` is large enough, so that data per thread `{NHWC / T}` is much larger than temp buffer per thread `{2NC}`
A threshold is defined to switch between the two implementations, which is found by tests.
The unit test for quantized group norm is modified to cover more cases.
**Performance test results**
Test Env:
- Intel® Xeon® CLX-8260
- 1 instance, 4 cores
- Using Jemalloc
Test method:
Create channels-last tensors as inputs, do group norm by
- Converting to contiguous then using NCHW kernel
- Using NHWC impl-1
- Using NHWC impl-2
- Using fp32 kernel (no quantization)
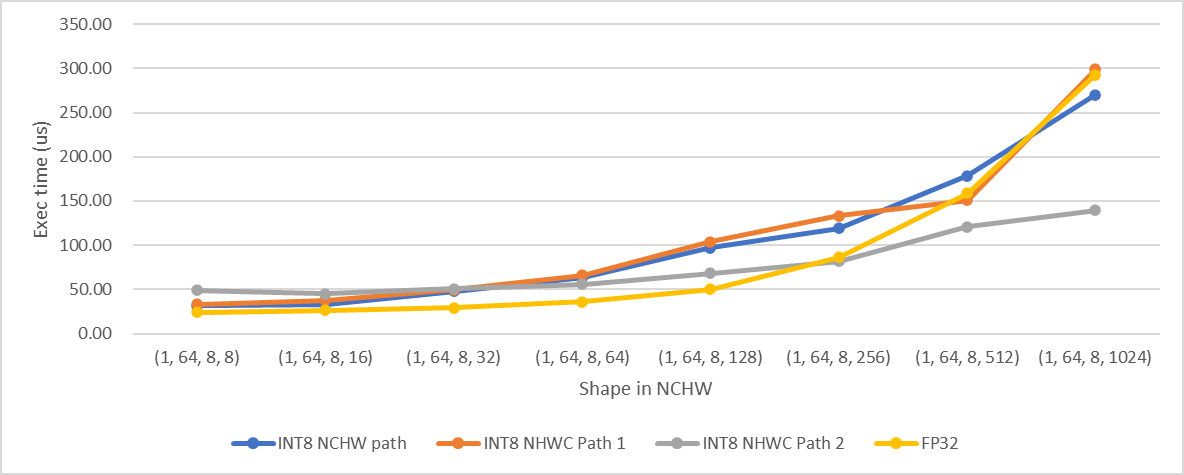
C=64
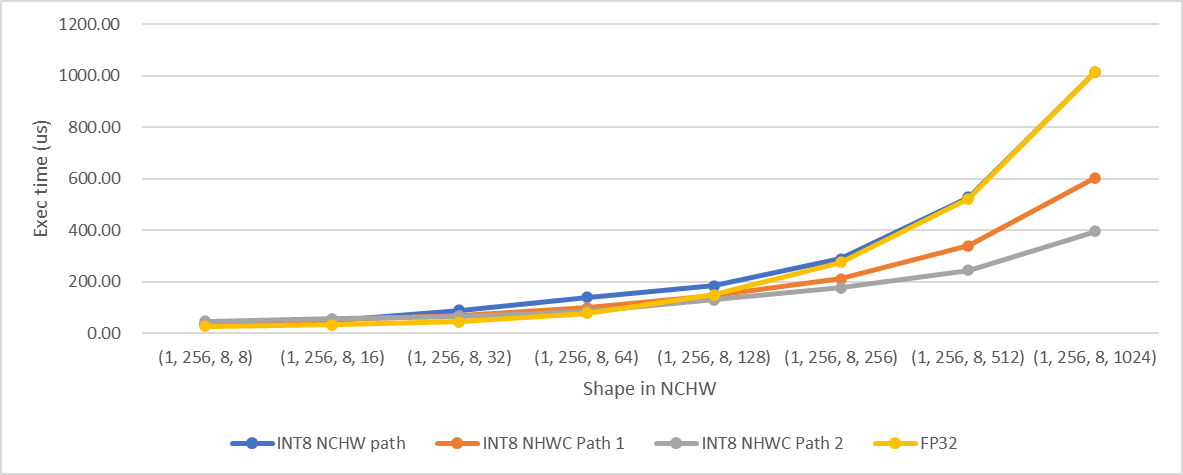
C=256
C=1024
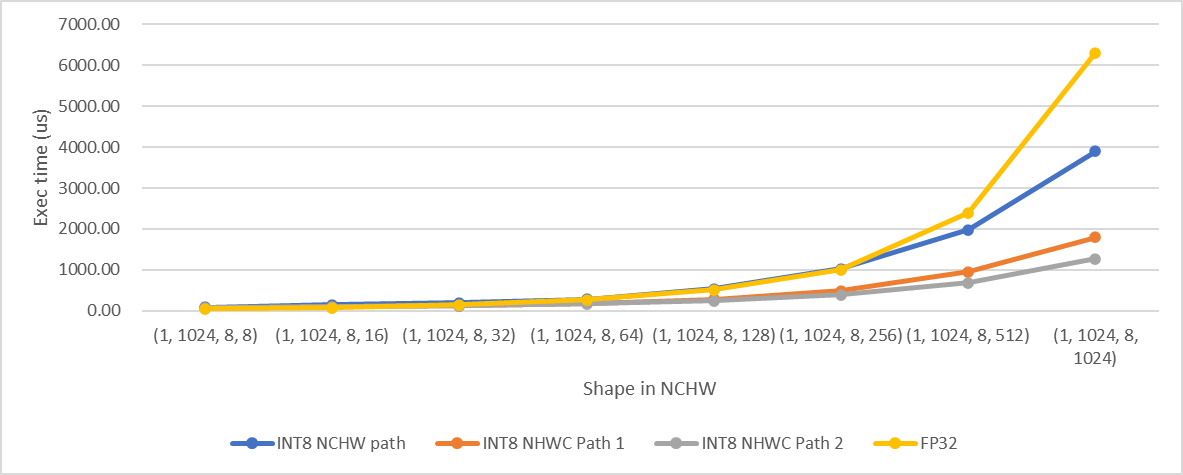
We selected 512 as the threshold as mentioned above according to the test results.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70520
Approved by: https://github.com/vkuzo
 pytorch
c1795977 - Add native impl for group norm on quantized CPU for channels-last inputs (#70520)
pytorch
c1795977 - Add native impl for group norm on quantized CPU for channels-last inputs (#70520)

