
pytorch
d82bc3fe - torch.flip via TI (#58747)
Commit
3 years agotorch.flip via TI (#58747)
Summary:
Implements an idea by ngimel to improve the performance of `torch.flip` via a clever hack into TI to bypass the fact that TI is not designed to work with negative indices.
Something that might be added is vectorisation support on CPU, given how simple the implementation is now.
Some low-hanging fruits that I did not implement:
- Write it as a structured kernel
- Migrate the tests to opinfos
- Have a look at `cumsum_backward` and `cumprod_backward`, as I think that they could be implemented faster with `flip`, now that `flip` is fast.
**Edit**
This operation already has OpInfos and it cannot be migrated to a structured kernel because it implements quantisation
Summary of the PR:
- x1.5-3 performance boost on CPU
- x1.5-2 performance boost on CUDA
- Comparable performance across dimensions, regardless of the strides (thanks TI)
- Simpler code
<details>
<summary>
Test Script
</summary>
```python
from itertools import product
import torch
from torch.utils.benchmark import Compare, Timer
def get_timer(size, dims, num_threads, device):
x = torch.rand(*size, device=device)
timer = Timer(
"torch.flip(x, dims=dims)",
globals={"x": x, "dims": dims},
label=f"Flip {device}",
description=f"dims: {dims}",
sub_label=f"size: {size}",
num_threads=num_threads,
)
return timer.blocked_autorange(min_run_time=5)
def get_params():
sizes = ((1000,)*2, (1000,)*3, (10000,)*2)
for size, device in product(sizes, ("cpu", "cuda")):
threads = (1, 2, 4) if device == "cpu" else (1,)
list_dims = [(0,), (1,), (0, 1)]
if len(size) == 3:
list_dims.append((0, 2))
for num_threads, dims in product(threads, list_dims):
yield size, dims, num_threads, device
def compare():
compare = Compare([get_timer(*params) for params in get_params()])
compare.trim_significant_figures()
compare.colorize()
compare.print()
compare()
```
</details>
<details>
<summary>
Benchmark PR
</summary>
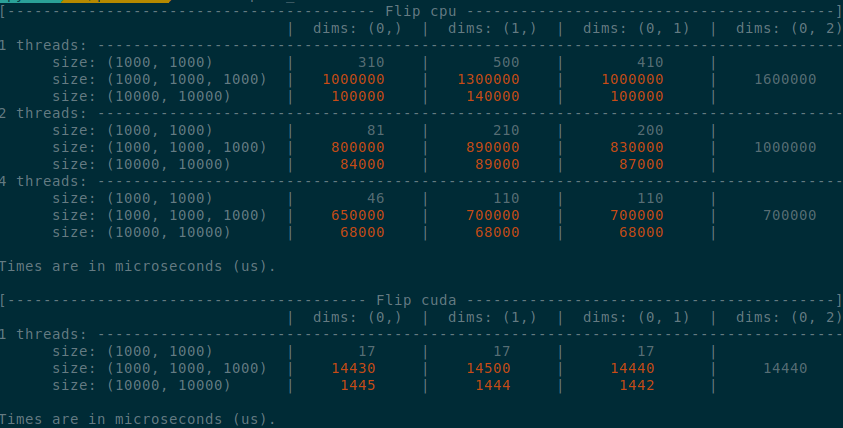
</details>
<details>
<summary>
Benchmark master
</summary>
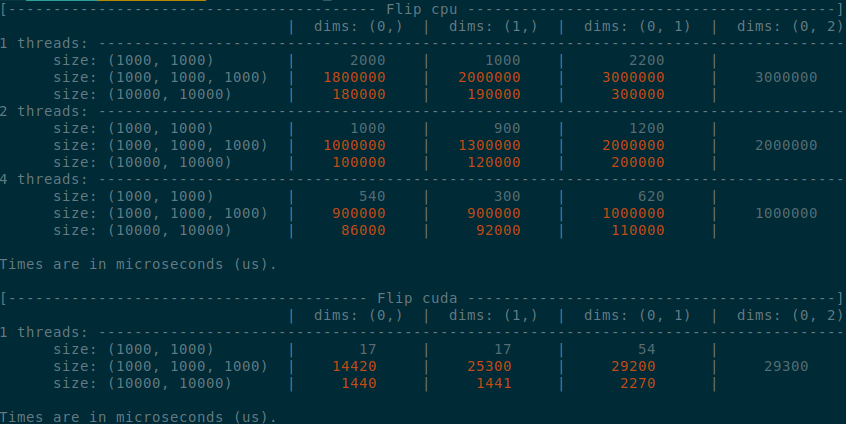
</details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58747
Reviewed By: agolynski
Differential Revision: D28877076
Pulled By: ngimel
fbshipit-source-id: 4fa6eb519085950176cb3a9161eeb3b6289ec575
Author

Committer

Parents
Loading