Cuda persistent softmax (#20827)
Summary:
Adds persistent cuda kernels that speed up SoftMax applied over the fast dimension, i.e. torch.nn.Softmax(dim=-1) and torch.nn.LogSoftmax(dim=-1). When the size is <= 1024, this code is 2-10x faster than the current code, speedup is higher for smaller sizes. This code works for half, float and double tensors with 1024 or fewer elements in the fast dimension. Numerical accuracy is on par with the current code, i.e. relative error is ~1e-8 for float tensors and ~1e-17 for double tensors. Relative error was computed against the CPU code.
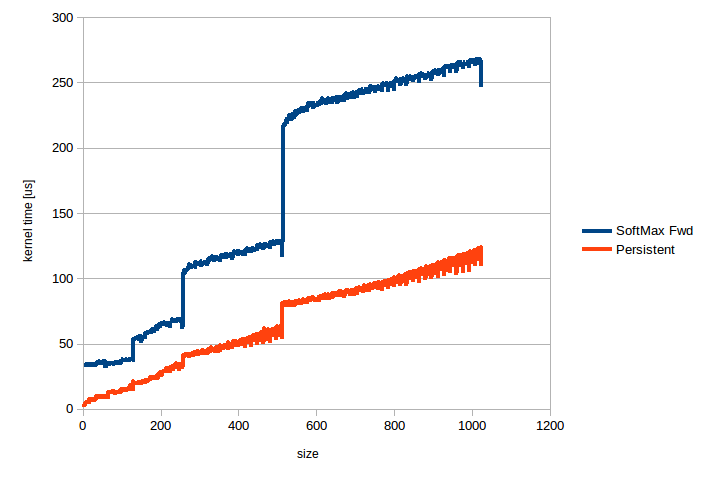
The attached image shows kernel time in us for torch.nn.Softmax(dim=-1) applied to a half precision tensor of shape [16384,n], n is plotted along the horizontal axis. Similar uplifts can be seen for the backward pass and for LogSoftmax.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20827
Differential Revision: D15582509
Pulled By: ezyang
fbshipit-source-id: 65805db37487cebbc4ceefb1a1bd486d24745f80


